저장 프로시저 하나를 돌리면서 인덱스의 중요성을 알게된 적이 있다. 그때 인덱스에 대해서 많이 찾아보고 알게된 것들이 많았는데 시간이 지날수록 금방 잊어버려서 다시 공부하는겸 인덱스에 대해서 정리해보려한다.
인덱스란
인덱스에 대해서 검색하면 항상 색인이라는 단어가 나온다. 실제로 색인은 영어로 index로 쓰이고 책에서 내용의 단어나 구절등의 위치가 몇페이지에 있는지 알려주는 정보의 목록인데, 개인적으로 책을 많이 읽지 않아서 그런지 색인이라는 단어가 굉장히 낯설게 느껴진다. 때문에 나처럼 책알못이라 색인이 와닿지 않는다면, 호텔의 x호 ~ x호는 왼쪽 x호 ~ x호 는 오른쪽으로 표시되어있는 화살표를 생각한다면 좀 더 와닿지 않을까 추측해본다.
방 호수를 의미하는 room_num이라는 컬럼에 인덱스를 추가했다고 가정하면, DB의 인덱스는 곧 화살표다. 우리는 그 화살표를 보고 범위를 줄여서 방을 금방 찾을 수 있는것 처럼 DB에서도 인덱스를 통해 해당 컬럼 값을 빠르게 찾을 수 있는 것이다. 인덱스의 동작 원리를 보면 좀 더 자세하게 알 수 있다.
동작 원리

이미지는 'SHOW INDEX 테이블' 쿼리를 실행 시 나온 결과 캡처 이미지다. 빨간색으로 표시한 index_type을 보면 해당 인덱스의 종류가 BTREE임을 알 수 있다. mysql의 공식 문서를 보면 Most Mysql Indexes are stored in B-trees라고 나와있기 때문에 저 BTREE는 B-TREE를 말하는게 아닐까 싶다.
https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html
MySQL :: MySQL 8.0 Reference Manual :: 8.3.1 How MySQL Uses Indexes
8.3.1 How MySQL Uses Indexes Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows. The larger the table, the more this cos
dev.mysql.com
개인적으로 아래 이미지가 가장 이해하기 쉬운 이미지라고 생각한다.
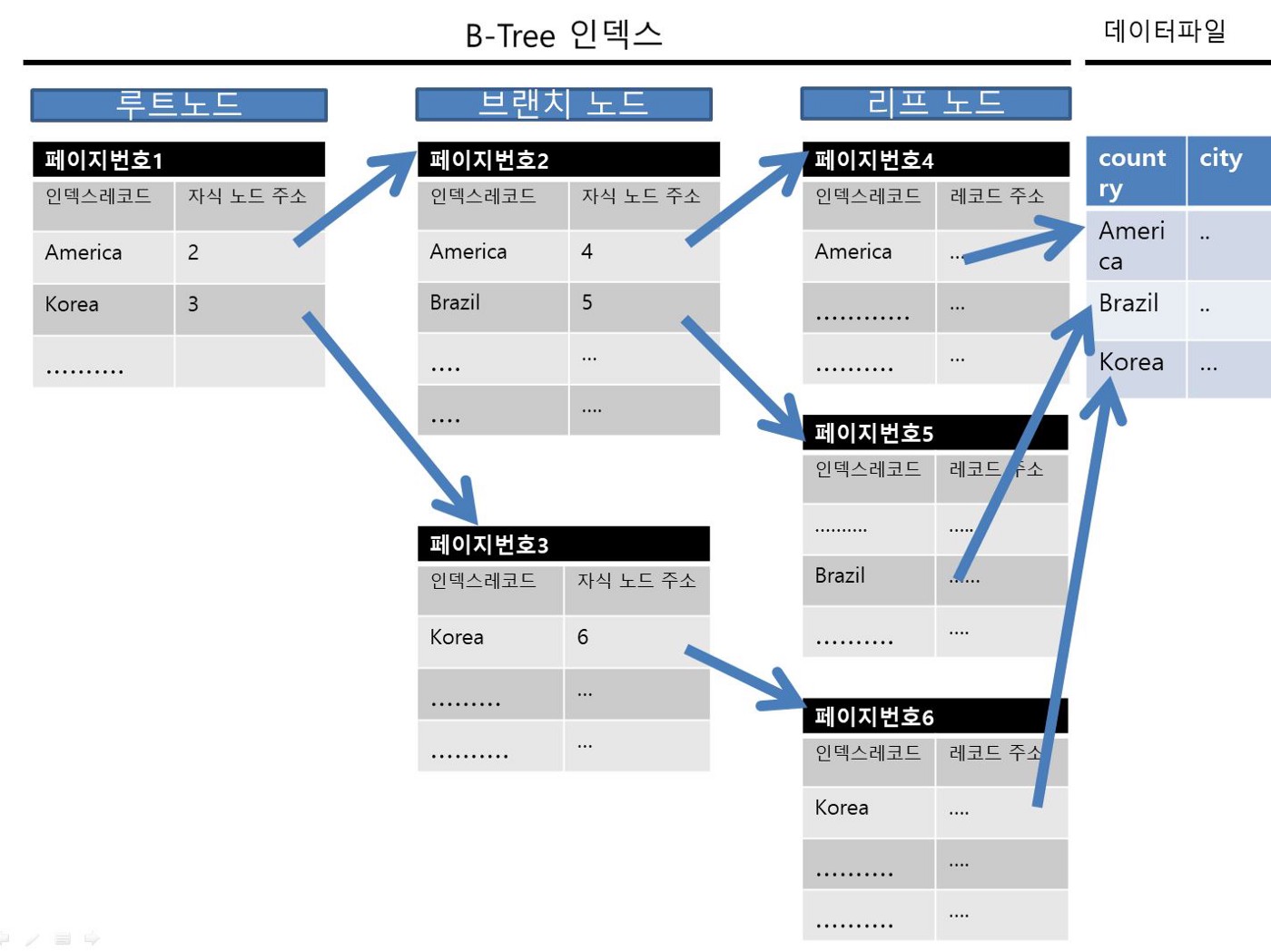
이미지 출처 : https://swknight13.medium.com/dbms-%EC%9D%98-%EC%9D%B8%EB%8D%B1%EC%8A%A4-b-tree-4ff039dca22
이미지를 보면 옆으로 누어져 있지만 트리 구조임을 알 수 있고, 각 노드는 Key-Value로 이루어진 여러 행으로 구성되어 있다. 참고로 노드 용량은 기본적으로 16KB라고 한다.
인덱스는 키값이 정렬된 트리구조로 동작하며 자식 노드의 수가 같은 Balanced Tree라고 한다.
가장 상단의 노드 (블럭 또는 페이지)를 루트(Root) 노드라고 하고 가장 하단의 페이지를 리프(Leaf) 노드라고 한다. 그리고 루트 노드와 리프 노드의 사이를 브랜치(Branch) 노드라고 한다.
간단하게 실제 데이터가 저장된 위치인 데이터 주소값은 리프 노드에만 존재하고, 루트부터 시작해서 범위를 줄여나가며 자식 노드의 주소값을 찾아 찾아 가는 원리로 생각한다. O(logN)
명령어
인덱스 조회
SHOW INDEX FROM 테이블
인덱스 추가
ALTER TABLE 테이블명 ADD INDEX 인덱스명(컬럼)
인덱스 삭제
ALTER TABLE 테이블명 DROP INDEX 인덱스명
테스트
국가별 IP 대역이 저장된 데이터로 테스트를 해봤다.
먼저 Show Index를 해보면

기본키가 기본적으로 인덱스가 생성되어 있는 것을 알 수 있다.
Mysql은 쿼리문 앞에 EXPLAIN을 붙이면 해당 쿼리 실행에 대한 정보를 볼 수 있다.
EXPLAIN SELECT * FROM CountryIp ci WHERE code = 'KR'위 쿼리는 code가 KR(대한민국)인 데이터를 조회하는 쿼리다.
EXPLAIN을 실행한 결과

type이 ALL인 것과, rows가 22830개라는 것을 확인할 수 있다.
CountryIp의 총 데이터수가 22830개인데, 이를 전체 스캔하기 때문에 상대적으로 쿼리 실행 시간이 큰 것이다.
때문에 인덱스를 추가하는것은 rows를 줄이는 것에 초점을 맞추고 이는 곧 성능 향상이라고 할 수 있다.
code에 인덱스를 추가한 후, EXPLAIN을 다시 실행한 결과

type과 Extra의 내용이 바뀌어 있고, 가장 중요한 rows가 2033으로 줄었다.
결과적으로는, 인덱스 추가 전 약 300ms에서 인덱스 추가 후 약 50ms로 실행 시간이 줄었기 때문에 하나의 인덱스 추가로 엄청난 효과를 얻은 것이다.
실제 현업에서 특히 로그 테이블의 경우는 어마어마한 양의 데이터가 존재할 것이다. 그만큼 인덱스의 효과가 더욱 클 것이고 WHERE절에 자주 사용되는 컬럼들에 인덱스를 추가한다면 상당한 성능 개선효과가 나오는 것이다.
인덱스 추가한 후 다시 Show Index를 해보면

idx_code가 생겼는데, Cardinality를 주목해야한다. Cardinality는 중복되지 않은 값의 개수를 나타내는데
예를 들면, CountryIp의 경우 code 컬럼에 564종류의 값이 있다. 만약 성별이라면 남녀이기 때문에 값이 2일 것이다.
인덱스의 Cardinality가 높을수록 rows가 더 감소하는 효과를 얻기 때문에 최대한 값이 구별된 컬럼에 인덱스를 추가하는 것이 중요하다.
또한 프로시저를 개선하면서 알게된 것은, 인덱스에 대해서 아예 몰랐을때 SELECT의 성능을 향상 시키고 INSERT, DELETE, UPDATE의 성능은 안좋아진다고만 알고있었다. 개인적으로는 어느 정도는 맞고 틀린 부분이 있다고 생각한다.
실제로 개선시켰던 프로시저는 UPDATE문이 포함되어 있었는데 WHERE절에 쓰이는 컬럼에 인덱스를 걸어준 결과 UPDATE문의 전체 실행 시간도 상당히 감소했기 때문이다.
이를 통해서 알게된 건 데이터를 삽입, 수정, 삭제하는 과정에 있어서는 인덱스에 대해서 추가로 이루어져야 하기 때문에 성능이 감소할 수 있지만, 방대한 데이터에 대해서 UPDATE, DELETE하는 쿼리의 WHERE절에 인덱스 컬럼이 사용된다면, 수정, 삭제할 데이터를 찾는 스캔 과정이 풀로 진행되는 풀스캔이 아니기 때문에 오히려 실행시간을 감소시킬 수 있는 것이다.
한마디로, 인덱스는 WHERE절이 쓰이는 쿼리라면 성능 향상 효과를 얻을 수 있고, 그게 아니라면 감소 효과를 얻는다고 생각하는게 맞는 것 같다.
다중 컬럼
인덱스는 아래와 같이 2개 이상의 15개 이하의 컬럼에 하나의 인덱스를 지정할 수 있다.
ALTER TABLE 테이블명 ADD INDEX 인덱스명(컬럼1, 컬럼2, ...)하나씩 여러개 생성하면될걸 왜 굳이 여러개를 한번에 지정할까? 생각을 해봤다.
검색을 해봤을땐, 단일 컬럼씩 여러개 인덱스보다 해당 컬럼들을 하나의 인덱스로 사용할 경우 성능이 더 좋다고 한다.
사실 나는 기존에 (컬럼1, 컬럼2) 처럼 다중 컬럼으로 인덱스를 생성한 후,
where에 컬럼1만 쓰거나 컬럼2만 사용하면 인덱스를 안탄다고 알고있었다. 이는 멍청멍청이다.
컬럼1와 같이 앞에 선언한 컬럼은 where에 컬럼1만 있어도 인덱스를 탄다.
예를 들면,
ALTER TABLE Board ADD Index idx_title(title, content)title과 content라는 컬럼에 인덱스를 추가하고, 아래와 같이 쿼리를 날렸을때 경우가 나뉘어진다.
select * FROM Board b where title = 'title' //인덱스 사용
select * FROM Board b where title like 'title' //인덱스 사용
select * FROM Board b where title like 'title%' //인덱스 사용
select * FROM Board b where title like '%title' //인덱스 사용 안함
select * FROM Board b where title like '%title%' //인덱스 사용 안함
select * FROM Board b where content = 'content' //인덱스 사용 안함
select * FROM Board b where content like 'content' //인덱스 사용 안함
select * FROM Board b where content like 'content%' //인덱스 사용 안함
select * FROM Board b where content like '%content' //인덱스 사용 안함
select * FROM Board b where content like '%content%' //인덱스 사용 안함
select * FROM Board b where content = 'content' AND title like 'title' //인덱스 사용
select * FROM Board b where content = 'content' OR title like 'title' //인덱스 사용 안함
select * FROM Board b where content like 'content' AND title like 'title%' //인덱스 사용
select * FROM Board b where content like 'content' AND title like '%title' //인덱스 사용 안함다중 컬럼으로 생성한 인덱스에서 앞에 선언한 인덱스만(title) 사용하는 경우, 둘다 사용하는(title, content) 경우에는 인덱스를 사용한다.
뒤에 선언된 컬럼만 사용하는 경우(content) 인덱스를 사용하지 않는다.
OR로 같이 사용하는경우 인덱스를 사용하지 않는다.
LIKE의 경우 %가 앞에 있으면 (%title, %title%) 인덱스를 사용하지 않는다.
'DB' 카테고리의 다른 글
| Mysql, MariaDB Incorrect string value 이모티콘 이모지 에러 (2) | 2021.09.27 |
|---|---|
| Mysql 문자열 나누기 SUBSTRING, SUBSTRING_INDEX (0) | 2021.09.16 |
| MySQL 이벤트 스케줄러 등록 (0) | 2021.08.25 |
| MongoDB 설치 - Window (0) | 2020.11.29 |

